







在前面几讲中,我们成功配置了openvino开发环境并运行了demo,相信大家在使用中对openvino已经有了一定的认识。在这一讲,我们一起来理解model optimize的工作原理并熟练掌握模型转换的方法。
Model Optimizer,即模型优化器,是一个跨平台的命令行工具。它可以将深度学习训练框架如Caffe、TensorFlow、MXNet训练后的模型转换为部署所需要的模型。
以下列出各种模型对应的待转换模型格式:
| --INPUT_MODEL | DIFFERENT MODELS |
|---|---|
| .caffemodel | for Caffe models |
| .pb | Tensorflow |
| .params | MXNet |
| .onnx | ONNX* |
不论每一个框架如何表示各自的模型,model optimizer都会将其转换成统一的IR格式档案(Intermediate-representation)。
IR格式档案包含两个档:
- .xml档:描述整个模型的拓扑,每个阶层、相连性以及参数值
- .bin档:包含每个层训练好的权重和偏置
根据不同的硬件设备,选择不同的优化方法,以节省运算时间和存储器的空间
大部分模型都被训练并存储为FP32格式,但有时设备装置可利用FP16来运算得更快。因此model optimizer可根据需求自动转换成权值不同的格式。
Model optimizer直接提供了卷积神经网络的加速方法,具体为线性操作的融合(Linear operations fusing)。
通常情况下,在训练CNN时我们通常会使用BN以加速收敛,而这些BN层实际上是一系列线性运算(加法、乘法)。在推理阶段,常用的一个trick是“吸BN”,Model optimizer已经为我们实现了这个操作。具体的操作过程我们可以看doc的介绍:
Step1, BatchNormalization and ScaleShift decomposition: in this stage, BatchNormalization layer is decomposed to Mul → Add → Mul → Add sequence, and ScaleShift layer is decomposed to Mul → Add layers sequence.
Step2, Linear operations merge: in this stage, the Mul and Add operations are merged into a single Mul → Add instance. For example, if there is a BatchNormalization → ScaleShift sequence in the topology, it is replaced with Mul → Add in the first stage. In the next stage, the latter is replaced with a ScaleShift layer if there is no available Convolution or FullyConnected layer to fuse into next.
Step3, Linear operations fusion: in this stage, the tool fuses Mul and Add operations to Convolution or FullyConnected layers. Note that it searches for Convolution and FullyConnected layers both backward and forward in the graph (except for Add operation that cannot be fused to Convolution layer in forward direction).
这里其实有两个过程:分解 + 合并。拿BN来说,BN层会被分解为一些列的Mul-->Add --> Mul -->Add操作(乘、加),然后将Mul-->Add操作合并成一个Mul-->Add,接着就会被优化器融合到卷积层中了~~
在使用model optimizer前,我们需要安装对应框架所需要的模型优化器,安装方法在《OpenVINO 的安装及配置》章节已讲述,大家可以参考。
这里我们以Intel官方提供的squeezene Caffe模型来演示转换过程。
既然需要转换squeezene Caffe模型,那么就应该找到该模型路径,我的是"C:\\Program Files (x86)\\Intel\\openvino_2021\\deployment_tools\\open_model_zoo\ ools\\downloader\\public\\squeezenet1.1\\squeezenet1.1.caffemodel",有的小伙伴找不到这个文件,没关系,另辟蹊径。
进入用户文件夹/document/Intel,这里存放着OpenVINO sample以及demos的编译结果,如果你还有印象的话。与此同时我们可以找到openvino_models,这个文件夹是在跑demo_squeezenet_download_convert_run.bat的时候自动下载的。
于是,在openvino_models\\models\\public\\squeezenet1.1中就存放着我们需要的caffe模型文件。
①以管理员身份运行cmd(否则转换时会出现权限不足!!)
这一点也是官方强调的:

②进入C:\\Program Files (x86)\\Intel\\openvino_2021\\deployment_tools\\model_optimizer文件夹;
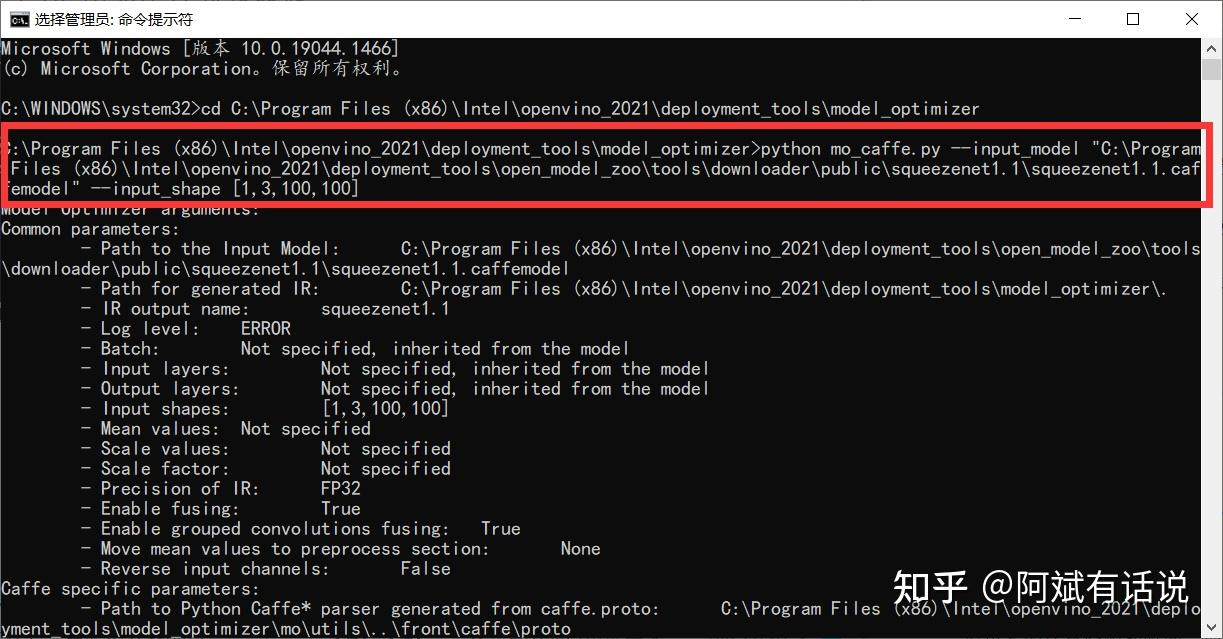
③cmd中执行以下命令,参数指定模型所在路径,输出路径默认优化器文件夹下:
python mo_caffe.py --input_model "C:\\Program Files (x86)\\Intel\\openvino_2021\\deployment_tools\\open_model_zoo\ ools\\downloader\\public\\squeezenet1.1\\squeezenet1.1.caffemodel"④观察结果
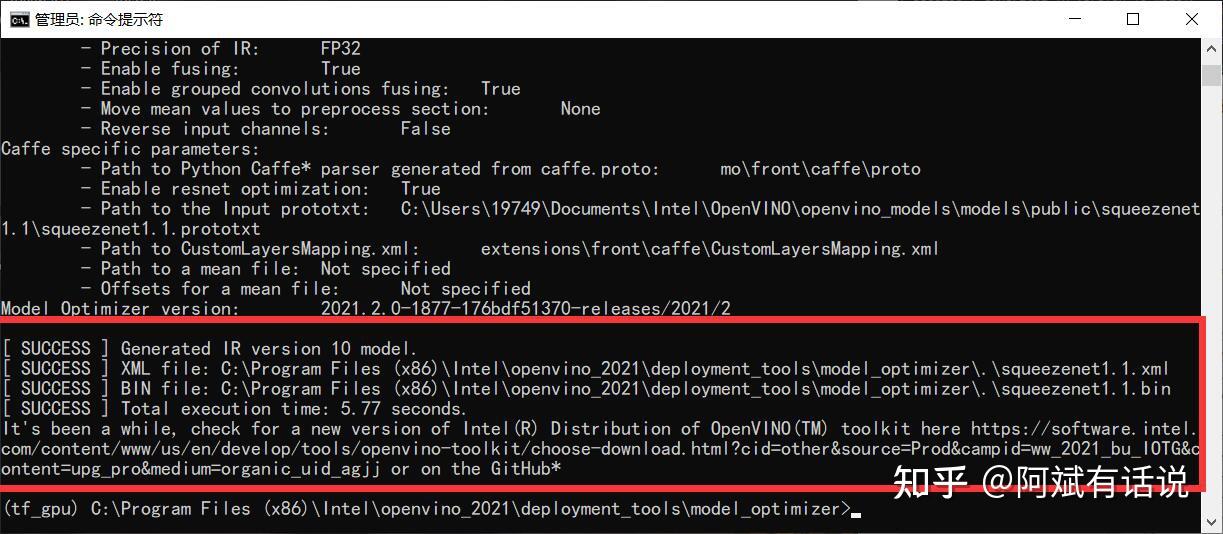
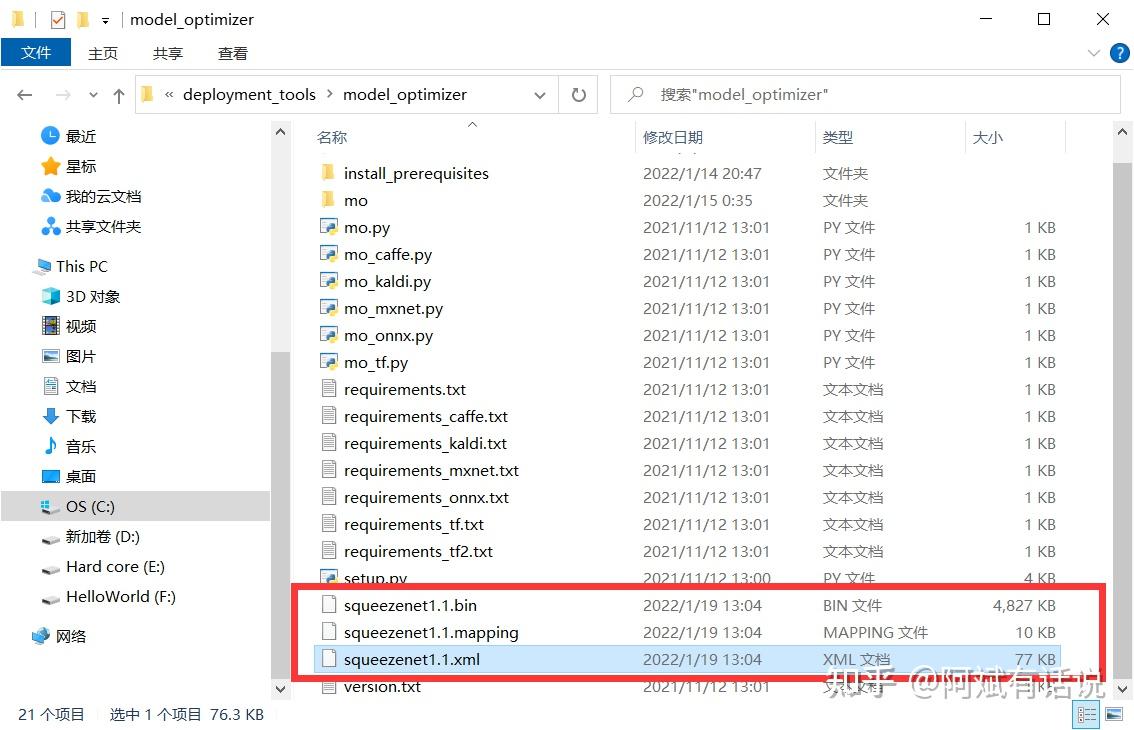
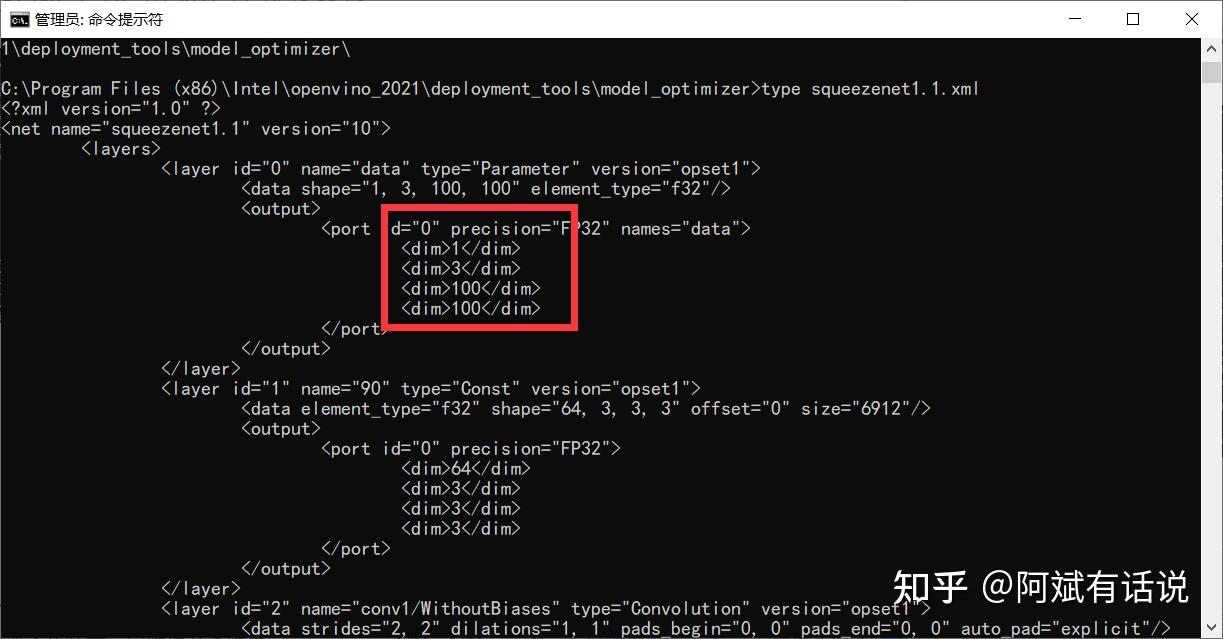
我们可以在model optimizer文件下中看到以下三个文件:
- Error1
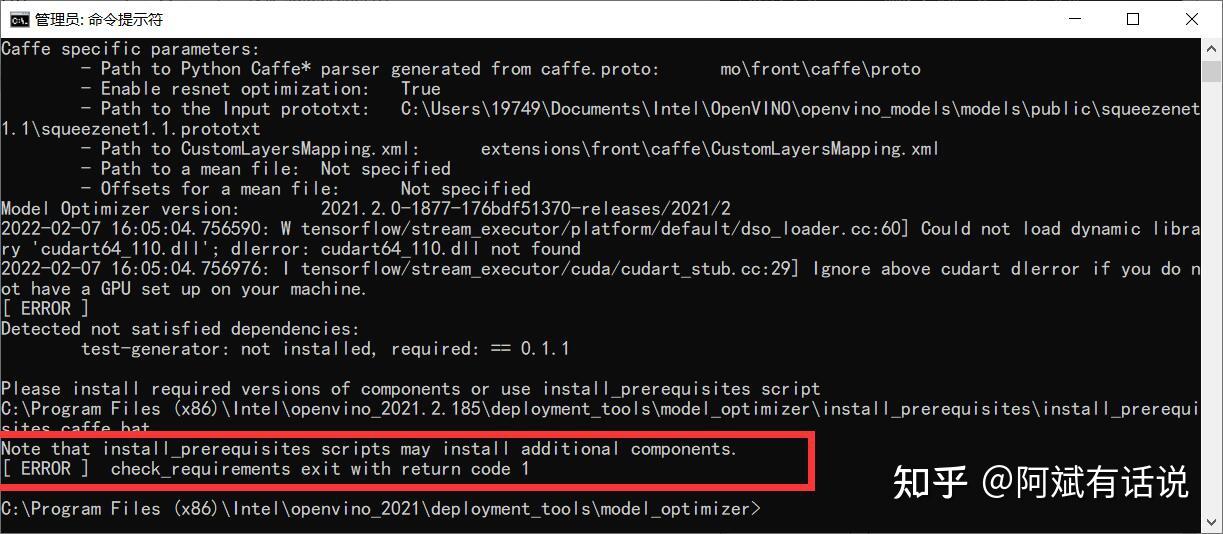
Reason:没有安装install_prerequisites需要的额外的组件
Method:如果模型优化器在虚拟环境中配置的话,可有利用conda激活;反之,可以看一下我这篇文章《OpenVINO2021 的安装及配置》,里面已经详细讲解安装方法啦~
Attention:由于OpenVINO发展迅速,现在最新的已经到了OpenVINO2022.3,但先前博主的文章是2021版本的,建议大家可以直接使用新版本~~不过小伙伴们也可以去看看博主写的旧版本配置,并给博主来一颗star~(2023.2.8更)
- Error2
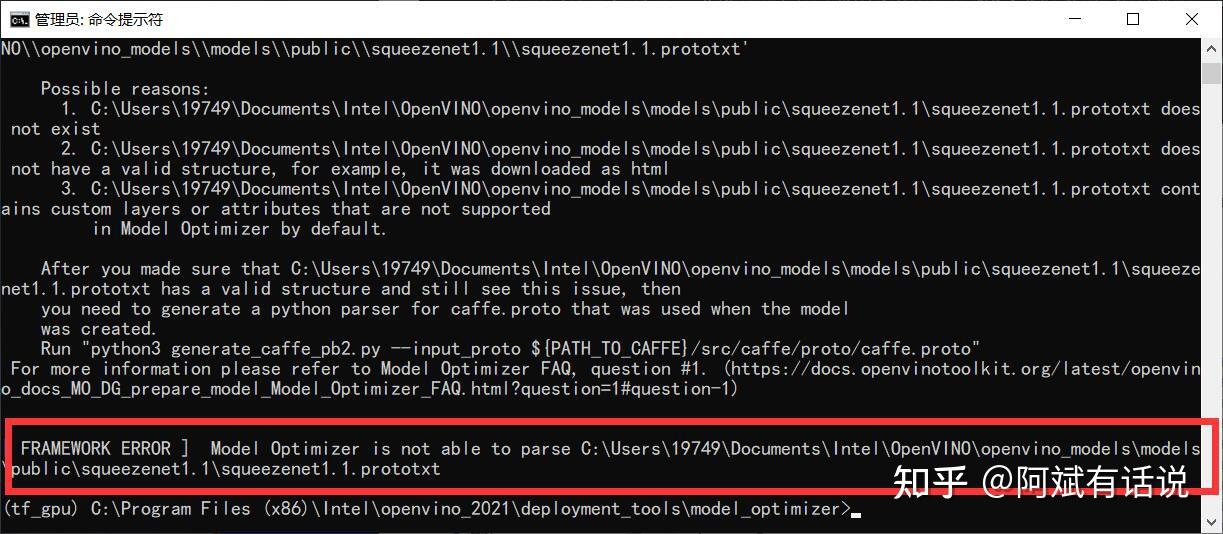
Reason:缺乏squeezenet1.1prototxt文件
Method:实际上该文件在先前执行demo时会自动下载,但受限于国内网络原因,很难成功。因此这里还是建议直接来我网盘下载~~
链接:https://pan.baidu.com/s/1G6urzy0P3hBNiMiNT9FQFA 提取码:2022
我们依然以caffe转换器为例,cmd中执行python mo_caffe.py --help/-h可以列出所有支持参数。
下面我们简单介绍几个常用的参数:
①--input_model:模型的输入路径,即训练后保存的模型,如tensorflow的pb文件
②--output_dir:模型输出路径,即产生的IR档案的位置
③--model_name:模型名字,针对同一个模型的输出可以建立多个不同版本的IR档案
④--input_shape[BS,C,W,H]:修改输入图片的尺寸 。其中各参数的含义为批处理量、通道数、图像尺寸(如果只需要修改批处理参数也可以使用 --batch 4,效果一致)。
⑤--reverse_input_channels:转换通道,从RGB→BGR(vice versa)
⑥--data_type:数据类型,该参数决定了模型的精度,包括INT8、 FP16 、 FP32(其精度逐渐递增)
演示如下:
分配给数据和权重的位数越多,它们表示的数值范围就越广 ,因此具有更高的模型准确性。然而数据越大,就需要更多的内存来存储,也需要更高的内存带宽,也需要更多的计算资源和时间。而且也不是每个设备都支持所有可能的格式 。
比如,CPU不支持FP16格式,而VPU只支持FP16格式;GPU支持FP16和FP32,且在前者上表现更好。
1.重塑网络的输入参数,尺寸与批处理量
2.剪切网络部分:在特定的阶层启动(--input)或者结束(--output)任务流程。
以squeezeCaffe为例,去掉第一层并从“pool1”层启动拓扑。
3.数据预处理:去均值化-mean_values、缩放图像数值
通过这一讲的学习,相信小伙伴们都能够对model optimizer建立自己的认知!有一点需要注意的是model optimizer是在推理以后执行的,因此它不会推理模型。在成功转换squeezenet1.1 caffe模型以后,大家可以尝试其他模型优化器,比如用mo_tf.py转化tensorflow导出的冻结图.pb文件!





