







数据库的查询优化器对查询性能有着非常重要的影响。查询优化这一个被研究了近四十多年的领域,因为它独有的复杂性,目前依旧有许多问题没有被很好地解决。前些年随着机器学习的兴起,数据库领域也频繁出现机器学习的相关技术的应用,其中查询优化领域就是一个重要的应用场景。
本文主要介绍SIGMOD 2021上两篇Best Paper《Bao: Making Learned Query Optimization Practical》[1]和《 Steering Query Optimizers: A Practical Take on Big Data》[2]的主要思想。相比于之前的机器学习的方法,这两篇paper所提出的方法是在已有查询优化器的基础上做了增强,在工程上更具可行性和可扩展性,可以让我们从另一个视角看待优化器。
优化器领域中Cardinality Estimation, Join Order, Cost Model等问题都是很重要但是目前没有非常完美解法的问题。因为Cardinality的估算不准导致优化器最终选择的执行计划质量不好的场景[3]也被专门研究过,并提出了JOB(Join Order Benchmark)这样数据分布存在倾斜的测试集用于评测优化器的优化能力。
早在2001年DB2 LEO就有了通过sql执行后反馈运行时数据的learning方式修正Cardinality来纠正优化器的错误执行计划选择,虽然因为效果不好并没有大规模使用,但是主要的Learning思想是有的,即从执行计划的实际效果好坏来反馈优化器以提升优化。
再到了近期的Neo[5]一个端到端的机器学习优化器,它通过一个神经网络取代了传统的优化器的Cardinality Estimation,Join Order选择,索引选择,算子的物理实现方式。主要思想是将SQL的执行计划先做Featurization,将Join Graph,Join Order,Column predicate等信息Encode到树型向量中,通过神经网络来评估整个执行计划的质量,其中会利用已有优化器来保证生成的执行计划是语义正确的。
Neo在JOB测试用取得了不错的效果,在多数场景下得到的执行计划比PostgreSQL优。Neo的缺点是整个网络的训练周期较长,在数据schema/workload变化后需要长时间的重新训练,如果优化器有改动例如添加新算子都不容易扩展,还有一点是支持的SQL范围也是有限的,例如只支持select-project-equijoin-aggregate形状的sql。
实际上Bao优化器的论文作者和Neo优化器的作者是同一批人,而Practical则是Bao这篇论文的一个关键词。相比于之前希望通过一个网络完全替代传统优化器这样的宏大愿景,Bao则提出了更接地气的做法,提供若干组Hint用于限制优化器的搜索空间,变相地得到若干个搜索空间不一样的优化器。最后利用机器学习选择使用哪一个优化器生成的执行计划。可以看出执行计划的生成是完全基于已有优化器的,这会带来很多工程上的优势,例如相比于端到端学习的黑盒优化器,Bao更加易于调试,只需要hint集成的代价更低,同时支持所有原优化器支持的SQL类型,更容易扩展新算子,训练速度更快。
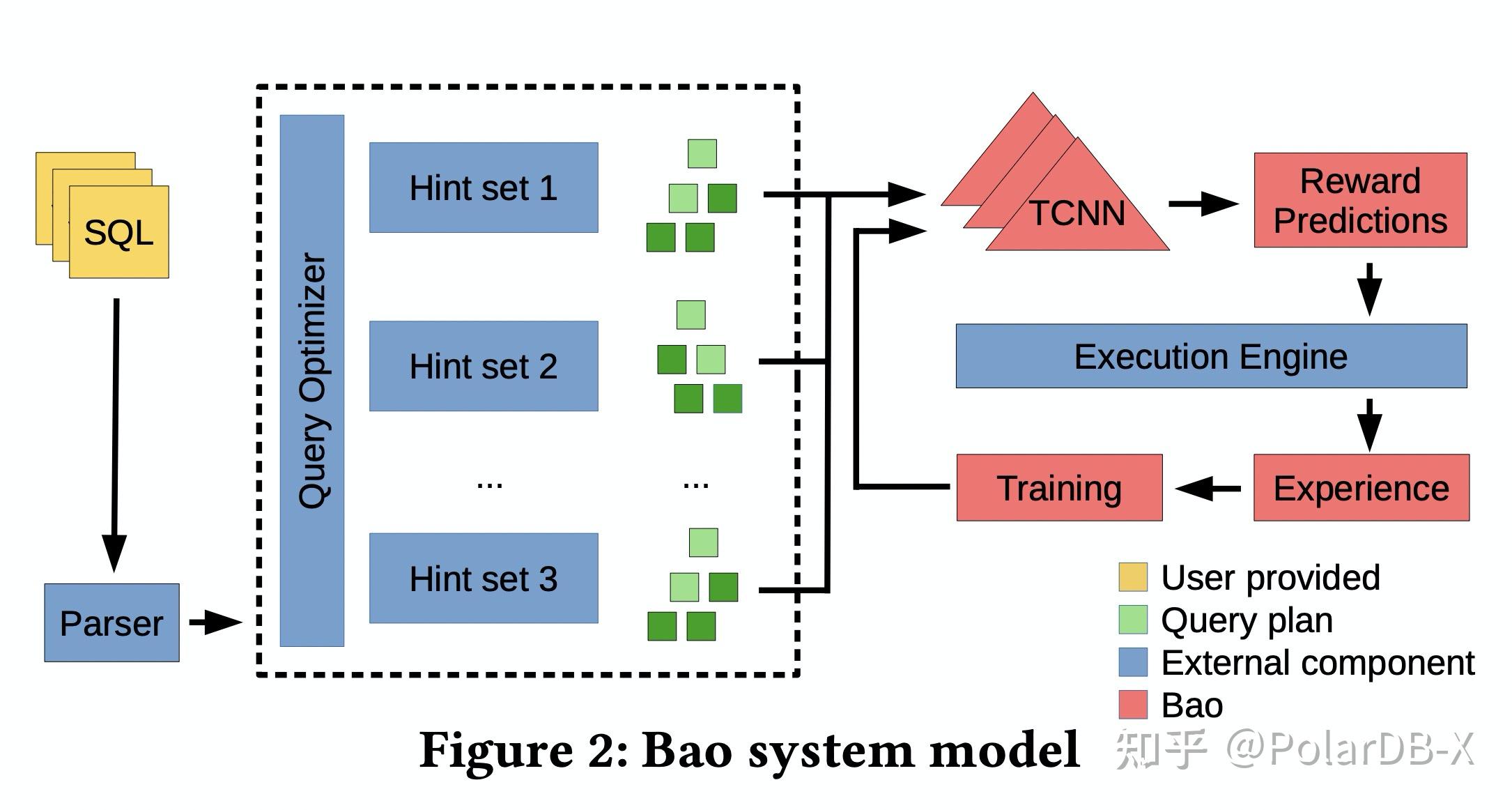
下面我们再来看看Bad整个模型是如何工作的。
论文提供了48组hint,hint是Join(hash join, Merge Join, Nested Loop Join)和Table Scan Access Path(sequence scan, index scan, index only scan)这几类全局优化开关的组合。例如一个重要的Hint组合就是禁止Nested Loop Join。由于hint是全局的,只要禁用了Nested Loop Join整个执行计划就会完全没有Nested Loop Join。我们马上会想到全局禁用不会导致局部最优解吗,确实会陷入局部最优解,但是如果选择局部禁用Nested Loop Join的话,hint的组合空间就会迅速随着Join的数目指数级膨胀。在最终的JOB实验测试效果看来,全局Hint也能够有非常好的效果。这也是这篇论文的一个重要Insight,只要通过全局的开关禁掉某些类算子的物理实现方式,优化器就能够非常大程度上避免糟糕的执行计划。顺带提及一下禁用Nested Loop Join这组hint对应优化器最终在JOB测试实验中占提升比例的35%,因为数据存在倾斜的情况,所以传统优化器的基于数据均匀分布的假设往往会导致Cardinality估算偏小,导致Nested Loop Join被选择。通过这一组hint可以避免优化器选陷入Cardinality估算不准的导致的Bad Plan。当然如果仅仅禁用Nested Loop Join则会导致其它查询陷入次优解中,因此我们需要通过机器学习的方法来评估每一组优化器对应的执行计划的好坏,最终解决上面的问题。
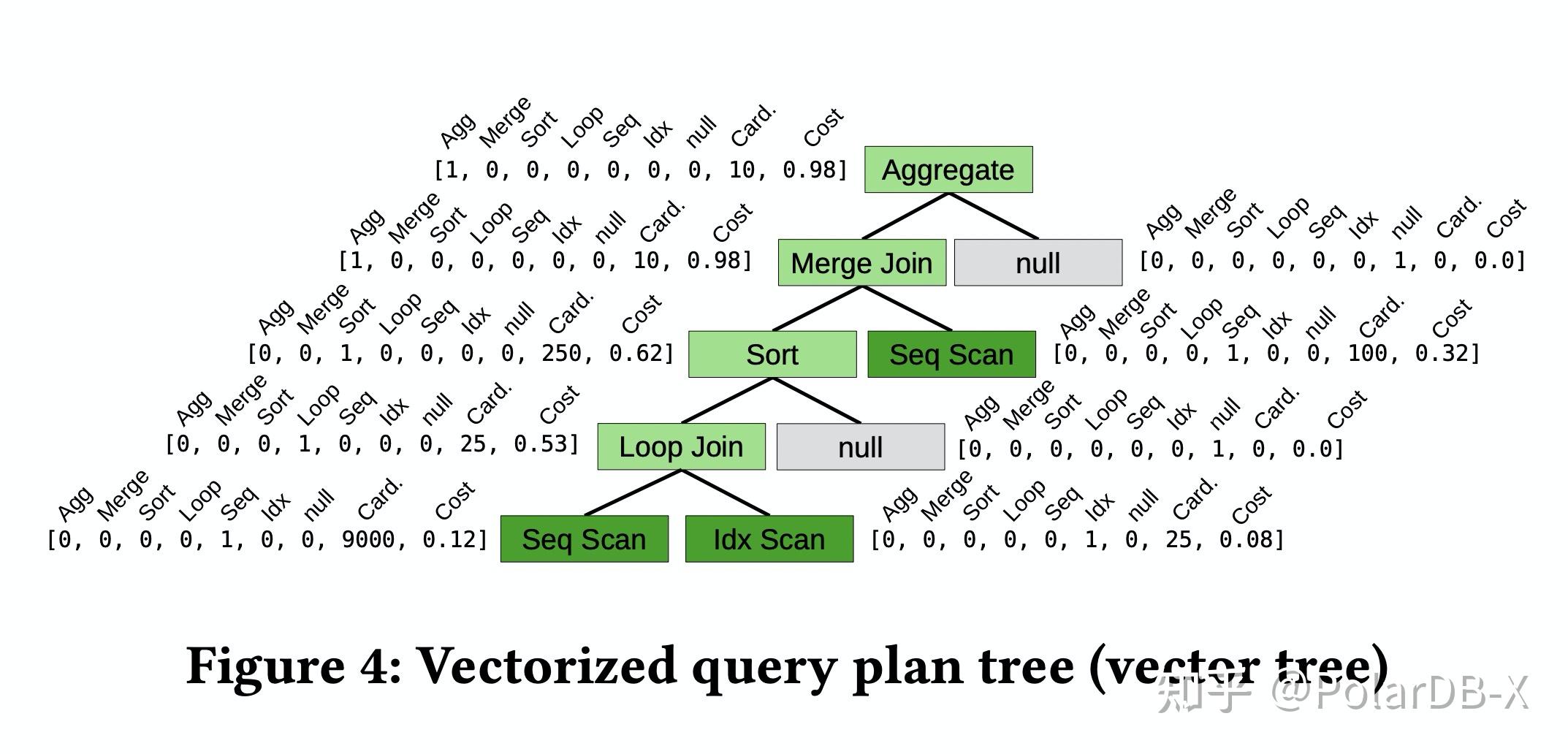
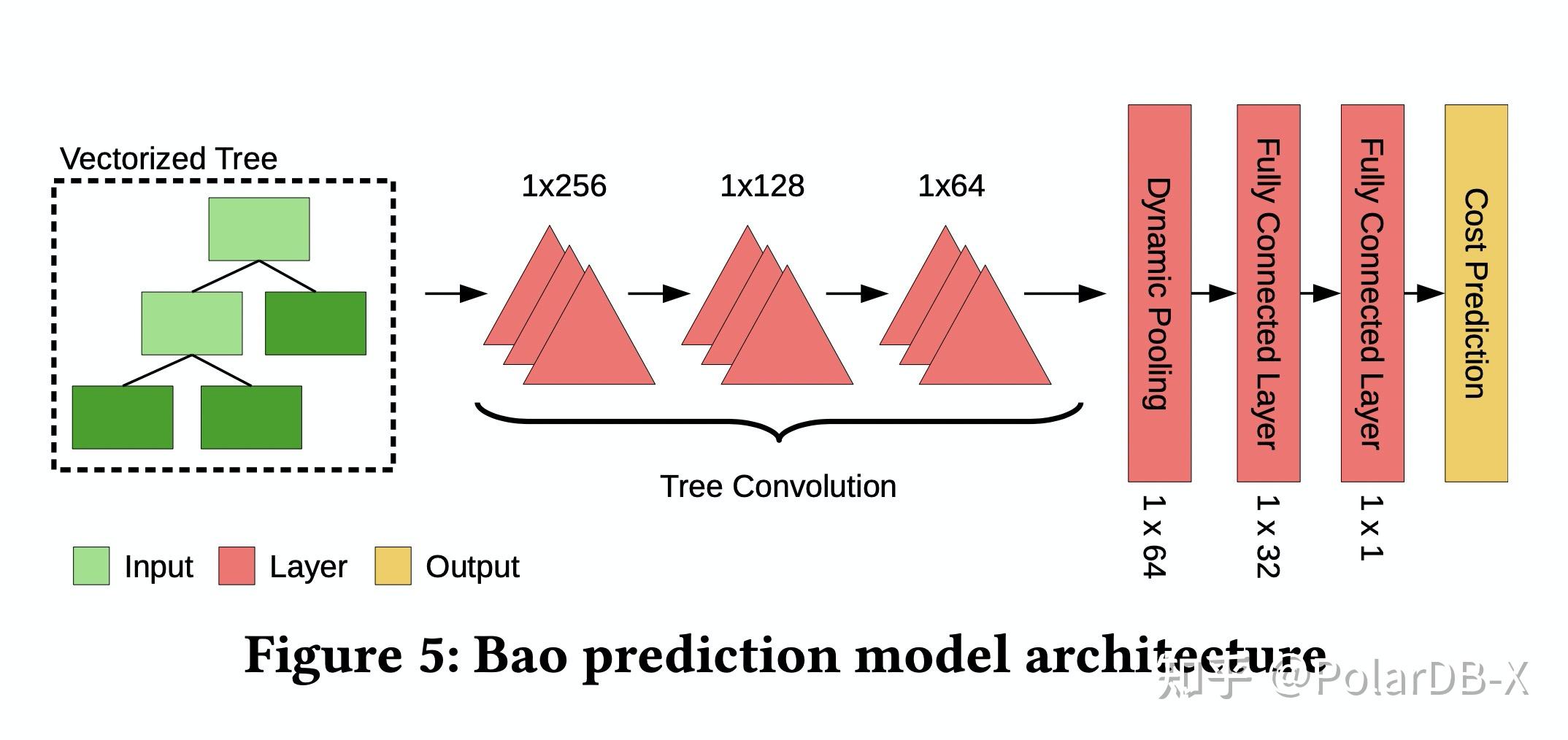
由于执行计划是树状的,因此网络采用了更具inductive bias的TCNN(Tree convolutional neural networks)作为执行计划代价的评估网络。执行计划先会经过Binarization把所有非二叉树结构的计划都转换成二叉树,再通过对树上每个节点信息进行编码(节点类型,Cardinality,Cost),最终通过TCNN和全连接层输出评估出的代价。通过这个网络预测的代价,选择多个优化器中最低网络预测代价的执行计划执行。
当执行计划执行完以后,会通过一个Thompson sampling的FeedBack Loop来修正模型以平衡Exploration和Exploitation。这里主要介绍一下FeedBack Loop的作用,熟悉强化学习的同学应该很清楚。Exploration对应于利用更多的随机性,探索更多模型预测以外的执行计划,避免陷入模型的局部最优解。Exploitation对应于利用好已有的网络,尽量选出期望代价最小的执行计划。平衡两者就是尽量利用已有模型的预测和避免局部最优解的权衡。
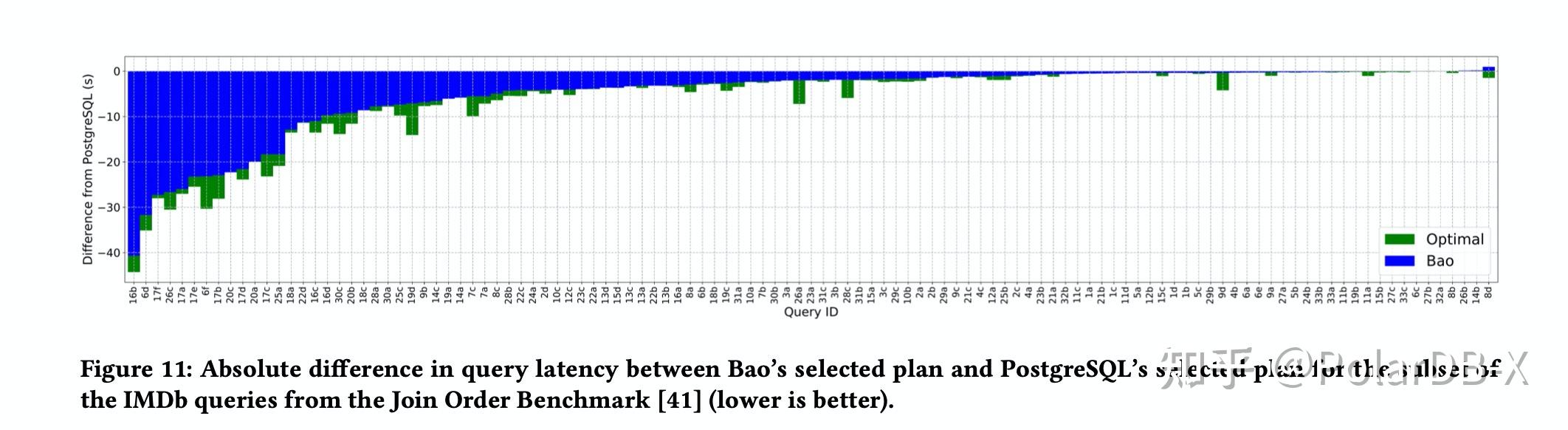
最终的在JOB测试的实验结果可以看出来绝大多数sql中都比原有PostgreSQL的优化器选出的执行计划要更优。Bao优化器也存在一些缺点,例如每次优化都要求每组hint对应的优化器做优化,虽然通过并行来提升速度,但这种场景不适用于OLTP场景,因为OLTP场景中大多数查询都是毫秒级别就完成的。Bao优化器更适用于OLAP场景,因为OLAP场景下查询会跑更长时间,优化时间百毫秒级别相比于执行时间可以忽略不算。值得注意的是Bao还有Advisor的部署模式,在这个模式下所有执行计划还是用原优化器的,但是用户可以通过Advisor获取Bao提供的Hint。
这篇论文是将Bao优化器中所采取的优化策略应用到了微软的大数据系统SCOPE里面,其中一大亮点是SCOPE的优化器是Cascades-style的优化器,不同于PostgreSQL优化器。在Cascades优化器中所有的优化都是通过优化规则实现的,优化规则的集合决定了搜索空间,SCOPE优化器有总共256条规则,其中包含了改写规则,join order规则,物理实现规则等等。把Bao的思想运用过来就从选择若干组hint变成了选择若干组优化规则,其它部分都一样。
我们可以看到由于SCOPE具有256条规则,除去非必要的规则有219条可以单独enable或disable的选项,总的规则集合子集可以有2^219种,不同于Bao只有48种hint组合,因此很有必要通过一种启发式的方式来裁剪规则集合,选出若干(例如1000)中不同的候选规则集合。SCOPE为此提出了Rule signature的概念:给定一个执行计划,它对应在优化过程中真正用到的规则集合即这个执行计划的Rule signature。还有Job span的概念:给定一条sql/job,所有通过enable/disable方式能够最终影响到最终执行计划的规则集合称为这条sql/job的job span。通过Job Span配合一些规则独立无依赖的假设和随机选择的方式将候选规则集合控制在了较小数量,从而可以最后可以将问题转换为Bao已解决的问题。
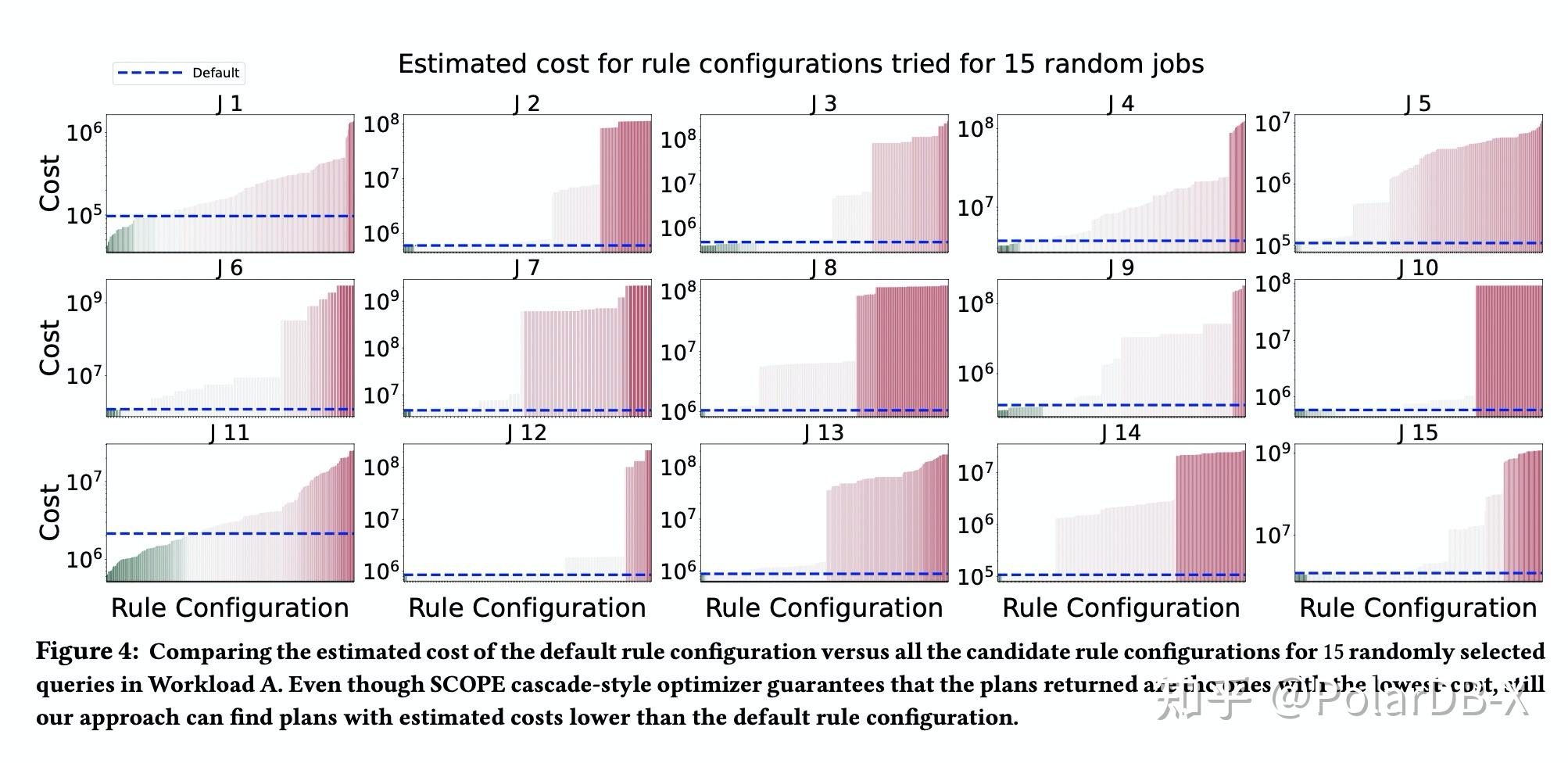
在这些规则集合中,论文作者发现了一个有意思点,当我们使用部分规则集合的时候,优化器得到最终的执行计划的代价居然比全部规则得到的执行计划代价要更低,乍眼一看有点匪夷所思,这岂不是和Cascade优化器能够找到给定代价模型下的最低代价的执行计划相违背吗?其实有过优化器开发经验的同学就会发现,在使用了动态规划的情况下这种情况是确实存在的,简单举个例子,每个算子都会有Cardinality的估算,但是Cardinality的估算是依赖于算子间的顺序的,例如不同的Join顺序计算出来的Cardinality值可能就不一样,甚至不同的Filter顺序也有可能计算出不一样的Cardinality。这样可以明白,当规则集合中少了部分规则的时候可能会影响到Cardinality值的计算,进而影响到了Cost的计算最终得到了Cost更低的执行计划。这里再次提一下,两篇论文都有一个Insight即关闭某些优化可以导致实际上更优的执行计划,因为关闭某些优化可以避免优化器因为错误的Cardinality估算和Cost模型偏差导致选择出差的执行计划。这篇论文后续讨论了在实际场景中如何根据利用rule signature 对job归类成group,加快在线新来sql的训练速度。由于本文更关注数据库优化器视角下有意思的点,具体的网络训练方式就不过多介绍。
传统查询优化器存在Cardinality估算不准,Cost模型存在偏差等问题,对于海量的查询sql无法每条都能够优化到完全完美,总会存在一些sql是会使得优化器估算错误。同时查询优化器经过了几十年的研究迭代,已然成为了一个非常复杂的模块,在上面调优通常会有牵一发而动全身的效果。同时它也是几十年研究后沉淀下来的结晶,其中有大量专家经验在里面。完全抛弃传统优化器,激进地通过机器学习方法替换会是一条不太现实的路。从这次介绍的两篇Paper中我们可以看到,保留传统的优化器,并在其之上通过机器学习的方法辅助解决传统优化器估算错误的case,这会是更加具有可行性的方法。
- Bao: Making Learned Query Optimization Practical
- Steering Query Optimizers: A Practical Take on Big Data Workloads
- How Good Are Query Optimizers, Really?
- LEO – DB2’s LEarning Optimizer
- Neo: A Learned Query Optimizer





